
Optimizing your AWS Serverless Costs
- Infrastructure & Architecture


Adriel HigorAdriel Higor
April 28, 2025 • 19 min read
When working on data-driven projects you often need to extract data from third-party sources, public APIs, or CSV files shared by other teams. However, before this data becomes useful, it typically requires cleaning, validation, and transformation before being loaded into a data warehouse for analytics, dashboards, machine learning, or any other use case you might have.
Knowing that, in this post, we'll walk through the basics of building a simple but effective ETL pipeline using AWS Lambda, Amazon S3, and Amazon RDS PostgreSQL. This post is not about creating the perfect and most optimized ETL solution but rather about demonstrating how AWS services can be used together to automate data processing in a straightforward way. By the end of this guide, you'll understand how to trigger a Lambda function to process data and store structured outputs in S3 for further analysis.
Github Repo: click here
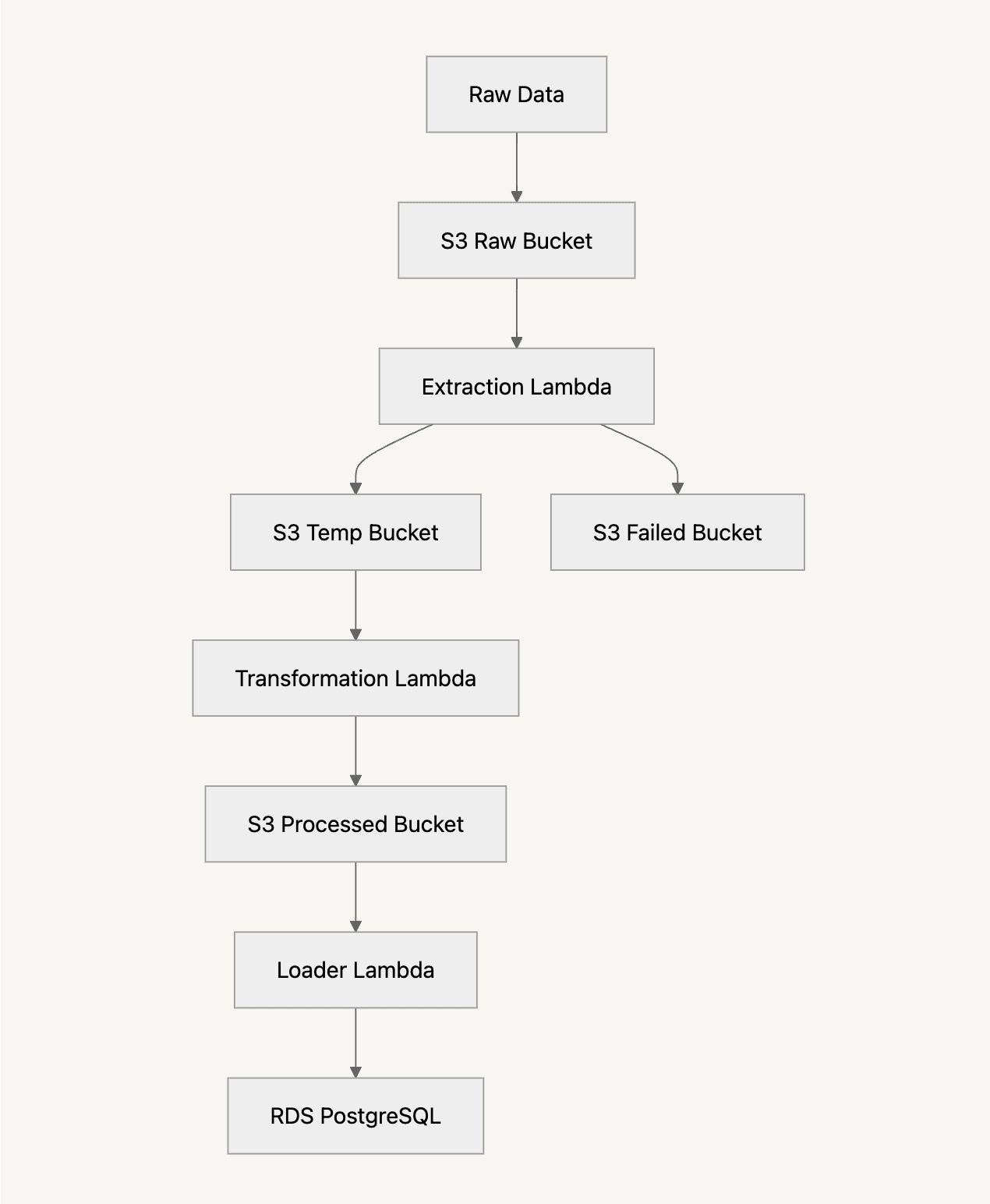
For our example pipeline, we will take a JSON file containing recipe information, validate the data and extract the necessary information, transform the extracted data into clean and query-ready data and finally load it into a PostgreSQL database where it will be ready to be used for any use case you might have.
Prerequisites
The template
The SAM template is the main file that defines the resources for our pipeline. It's a YAML file that describes the AWS resources and their properties. To start, we will create the structure of the template.
AWSTemplateFormatVersion: "2010-09-09"
Description: ETL Pipeline for Recipe Processing
Transform: AWS::Serverless-2016-10-31
Parameters:
Environment:
Type: String
Default: dev
RDSPostgreSQLHost:
Type: String
Default: localhost
RDSPostgreSQLPort:
Type: String
Default: "5432"
RDSPostgreSQLDBName:
Type: String
Default: postgres
RDSPostgreSQLUsername:
Type: String
Default: postgres
RDSPostgreSQLPassword:
Type: String
Default: postgres
RDSPostgreSQLSchema:
Type: String
Default: public
RDSPostgreSQLTable:
Type: String
Default: recipes
Resources: ...
This is a good starting point, it defines the environment variable that we will use to deploy the template to different environments, but it's still empty. We need to add the resources here for it to be useful.
First, we need to create a Lambda execution role that will allow the Lambda functions to access the necessary resources.
Resources:
...
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: LambdaExecutionPolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
- s3:ListBucket
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: "*"
In this step we are defining the policy that will allow the Lambda functions to access the necessary resources. We are allowing the Lambda functions to get, put, and list objects in the S3 buckets as well as to create log groups and log streams in CloudWatch.
Now that we have the necessary IAM roles, we can create the S3 buckets that will store the raw data, the temporary data, the failed data, and the processed data.
Resources:
...
RawRecipesBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "raw-recipes-data-${Environment}"
AccessControl: Private
TempRecipesBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "temp-recipes-bucket-${Environment}"
AccessControl: Private
FailedRecipesBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "failed-recipes-bucket-${Environment}"
AccessControl: Private
ProcessedRecipesBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "processed-recipes-bucket-${Environment}"
AccessControl: Private
Here we define the 4 buckets that we will use in our pipeline. We will use the !Sub intrinsic function to dynamically create the bucket names using the Environment parameter defined in the Parameters section. Also, we set the AccessControl property to Private, so no one can access the buckets without the proper permissions.
With the buckets and IAM roles created we can proceed and create our Lambda functions. In this case we will create 3 Lambda functions:
extraction-lambda: Where we will extract the data from the raw data transformation-lambda: Where we will transform the data loader-lambda: Where we will load the data into the RDS PostgreSQL database ...
Resources:
... # Our recently created buckets
DataExtractionLambda:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "extraction-lambda-${Environment}"
Handler: data_extraction.lambda_handler
Runtime: python3.9
CodeUri: lambdas/data_extraction/
Role: !GetAtt LambdaExecutionRole.Arn
Environment:
Variables:
RAW_BUCKET: !Ref RawRecipesBucket
TEMP_BUCKET: !Ref TempRecipesBucket
FAILED_BUCKET: !Ref FailedRecipesBucket
Timeout: 300
MemorySize: 512
DataTransformationLambda:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "transformation-lambda-${Environment}"
Handler: data_transformation.lambda_handler
Runtime: python3.9
CodeUri: lambdas/data_transformation/
Role: !GetAtt LambdaExecutionRole.Arn
Environment:
Variables:
TEMP_BUCKET: !Ref TempRecipesBucket
PROCESSED_BUCKET: !Ref ProcessedRecipesBucket
Timeout: 300
MemorySize: 512
DataLoaderLambda:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub "loader-lambda-${Environment}"
Handler: data_loader.lambda_handler
Runtime: python3.9
CodeUri: lambdas/data_loader/
Role: !GetAtt LambdaExecutionRole.Arn
Environment:
Variables:
RDS_HOST: !Ref RDSPostgreSQLHost
RDS_PORT: !Ref RDSPostgreSQLPort
RDS_DB_NAME: !Ref RDSPostgreSQLDBName
RDS_USERNAME: !Ref RDSPostgreSQLUsername
RDS_PASSWORD: !Ref RDSPostgreSQLPassword
RDS_SCHEMA: !Ref RDSPostgreSQLSchema
RDS_TABLE: !Ref RDSPostgreSQLTable
PROCESSED_BUCKET: !Ref ProcessedRecipesBucket
Timeout: 300
MemorySize: 512
# Create permissions for S3 buckets to invoke Lambda functions
RawBucketPermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref DataExtractionLambda
Principal: s3.amazonaws.com
SourceArn: !GetAtt RawRecipesBucket.Arn
TempBucketPermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref DataTransformationLambda
Principal: s3.amazonaws.com
SourceArn: !GetAtt TempRecipesBucket.Arn
ProcessedBucketPermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref DataLoaderLambda
Principal: s3.amazonaws.com
SourceArn: !GetAtt ProcessedRecipesBucket.Arn
Here we define the 3 Lambda functions and the notification function that we will use in our pipeline. We will use the !GetAtt LambdaExecutionRole.Arn intrinsic function to get the ARN of the Lambda execution role that we will create in the next step.
We are also defining the events that will trigger the Lambda functions. The DataExtractionTrigger will trigger the DataExtractionLambda when a new object is created in the RawRecipesBucket. The DataTransformationTrigger will trigger the DataTransformationLambda when a new object is created in the TempRecipesBucket. The DataLoaderTrigger will trigger the DataLoaderLambda when a new object is created in the ProcessedRecipesBucket.
The CodeUri property is the path to the Lambda function code in the lambdas folder that we will create soon.
Resources:
...
# Create notifications through CloudFormation custom resources
NotificationFunction:
Type: AWS::Serverless::Function
Properties:
Handler: notification_handler.lambda_handler
Role: !GetAtt NotificationFunctionRole.Arn
Runtime: python3.9
Timeout: 30
CodeUri: lambdas/notification_handler/
# Custom resource Lambda role for S3 notifications
NotificationFunctionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: S3BucketNotificationPolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:PutBucketNotification
- s3:GetBucketNotification
- s3:PutBucketNotificationConfiguration
Resource: '*'
# S3 bucket notification configurations
RawBucketConfiguration:
Type: Custom::S3BucketNotification
DependsOn:
- RawBucketPermission
- DataExtractionLambda
Properties:
ServiceToken: !GetAtt NotificationFunction.Arn
BucketName: !Ref RawRecipesBucket
NotificationConfiguration:
LambdaFunctionConfigurations:
- Events: ["s3:ObjectCreated:*"]
LambdaFunctionArn: !GetAtt DataExtractionLambda.Arn
TempBucketConfiguration:
Type: Custom::S3BucketNotification
DependsOn:
- TempBucketPermission
- DataTransformationLambda
Properties:
ServiceToken: !GetAtt NotificationFunction.Arn
BucketName: !Ref TempRecipesBucket
NotificationConfiguration:
LambdaFunctionConfigurations:
- Events: ["s3:ObjectCreated:*"]
LambdaFunctionArn: !GetAtt DataTransformationLambda.Arn
ProcessedBucketConfiguration:
Type: Custom::S3BucketNotification
DependsOn:
- ProcessedBucketPermission
- DataLoaderLambda
Properties:
ServiceToken: !GetAtt NotificationFunction.Arn
BucketName: !Ref ProcessedRecipesBucket
NotificationConfiguration:
LambdaFunctionConfigurations:
- Events: ["s3:ObjectCreated:*"]
LambdaFunctionArn: !GetAtt DataLoaderLambda.Arn
The NotificationFunction is a CloudFormation custom resource used here to handle the S3 bucket notifications during the stack deployment.
The NotificationFunctionRole is the IAM role that will be used to trigger the Lambda functions.
The RawBucketConfiguration, TempBucketConfiguration, and ProcessedBucketConfiguration are the custom resources that will be used to trigger the Lambda functions when a new object is created in the S3 buckets.
Note: This Function was added because when using native S3 Event Notifications alone with CloudFormation, the deployment process Failed due to circular dependencies between the S3 buckets and the Lambda functions. Thanks to wjordan for the workaround.
Now that we have the Lambda functions created, we can proceed and create the RDS PostgreSQL database.
Resources:
...
RDSPostgreSQL:
Type: AWS::RDS::DBInstance
Properties:
DBInstanceIdentifier: !Sub "rds-postgresql-${Environment}"
Engine: postgres
EngineVersion: "16.8"
DBParameterGroupName: !Ref RDSPostgreSQLParameterGroup
DBInstanceClass: db.t3.micro
DBName: !Ref RDSPostgreSQLDBName
MasterUsername: !Ref RDSPostgreSQLUsername
MasterUserPassword: !Ref RDSPostgreSQLPassword
AllocatedStorage: 20
StorageType: gp2
StorageEncrypted: true
MaxAllocatedStorage: 20
PubliclyAccessible: true
DeletionProtection: false
Here we define the RDS PostgreSQL database that we will use in our pipeline. We are using the !Ref RDSPostgreSQLParameterGroup intrinsic function to get the parameter group that we will create in the next step.
Now that we have the RDS PostgreSQL database created, we can proceed and create the parameter group.
Resources:
...
RDSPostgreSQLParameterGroup:
Type: AWS::RDS::DBParameterGroup
Properties:
DBParameterGroupName: !Sub "rds-postgresql-parameter-group-${Environment}"
Family: postgres15
Description: Parameter group for RDS PostgreSQL
Parameters:
max_connections: 100
shared_preload_libraries: pg_cron
cron.database_name: postgres
Here we define the parameter group that we will use in our RDS PostgreSQL database. We are using the !Sub intrinsic function to dynamically create the parameter group name using the Environment parameter defined in the Parameters section.
Now that we have all the components in place, here's how the complete pipeline works:
Raw JSON files are uploaded to the raw-recipes-bucket
The S3 event triggers the extraction Lambda function via the custom notification resource
The extraction Lambda:
The transformation Lambda is triggered by new files in the temp-recipes-bucket
The transformation Lambda:
The loader Lambda is triggered by new files in the processed-recipes-bucket
The loader Lambda:
To enhance this pipeline, consider adding:
This post covered the basics of building a serverless ETL pipeline using AWS Lambda, S3, and RDS PostgreSQL. We walked through the process of creating the necessary IAM roles, S3 buckets, Lambda functions, and RDS PostgreSQL database. Although we faced some issues with the S3 Event Notifications that required us to create some workarounds, overall, this was a fun project to work on it shows us how we can simplify our life as software engineers by using existing tools and services in available in the AWS ecosystem in our favor to build scalable and efficient systems, with minor headaches in some of the integrations, but overall it was a great experience to be able to explore these resources.

